

Featured Resources
-
STORM Therapeutics: From Lead to Pre-Candidate Nomination in 18 Months

STORM Therapeutics: From Lead to Pre-Candidate Nomination in 18 Months
Case study
📣From lead to pre-candidate nomination in 18 months. Explore the STORM Therapeutics case study










July 30, 2015

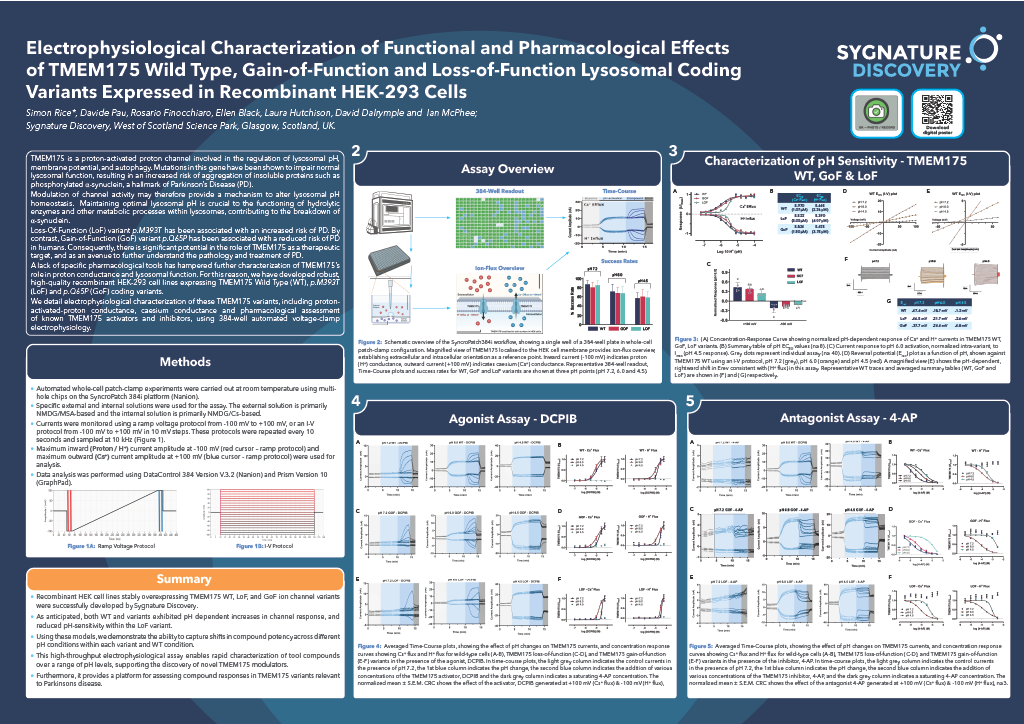
Inobrodib, an exciting, first-in-class oral anti-cancer drug in clinical development by CellCentric, was collaboratively designed, synthesised and supported on its pre-clinical journey by an integrated project team at Sygnature Discovery. Inobrodib is now showing promising results in Phase I and II trials for multiple myeloma and other cancer types.

At Sygnature Discovery, we deliver world-leading drug discovery solutions to accelerate your compound from idea to clinic.

Our leadership team brings diverse experience and insight, driving collaboration and innovation across drug discovery.

Explore careers at Sygnature Discovery and join a global team committed to science, collaboration, and integrity.
Inobrodib, an exciting, first-in-class oral anti-cancer drug in clinical development by CellCentric, was collaboratively designed, synthesised and supported on its pre-clinical journey by an integrated project team at Sygnature Discovery. Inobrodib is now showing promising results in Phase I and II trials for multiple myeloma and other cancer types.
At Sygnature Discovery, we deliver world-leading drug discovery solutions to accelerate your compound from idea to clinic.
Our leadership team brings diverse experience and insight, driving collaboration and innovation across drug discovery.
Explore careers at Sygnature Discovery and join a global team committed to science, collaboration, and integrity.

The identification of lead compounds is a pivotal moment of a drug discovery program. It can often be achieved through modifications to prior art with published ligands, natural products or endogenous ligands as key starting points.
However, when the target of interest is novel or underexplored, the availability of known ligands may be limited, or they may have have properties ill-suited for development into lead compounds. In these cases a screening approach can be used to identify hit compounds.
High throughput screening (HTS) of compound libraries has been driven through the advances in robotics and automation and now plays a central role in identifying hits suitable for lead optimisation. An alternative screening approach is fragment based screening, involving compounds with lower molecular weight (M.W.) and lower lipophilicity (LogP) than most HTS compounds.
At Sygnature Discovery we are building a lead-like screening library, through the purchase of commercial compounds (LeadFinder Library) and the synthesis of novel proprietary compounds. Additionally a fragment library which overlaps our HTS library is also offered as part of our overall screening platform.
Processing…
Thank you! Your download will begin shortly.





Peak Proteins, NuChem Sciences, and SB Drug Discovery have now fully integrated with Sygnature Discovery.
