

Featured Resources
-
STORM Therapeutics: From Lead to Pre-Candidate Nomination in 18 Months

STORM Therapeutics: From Lead to Pre-Candidate Nomination in 18 Months
Case study
📣From lead to pre-candidate nomination in 18 months. Explore the STORM Therapeutics case study






Discover precise insights into brain neurochemistry with Sygnature Discovery's in vivo microdialysis and cOFM services. With over 20 years of expertise, we design bespoke studies that reveal how compounds modulate neurotransmitter systems in health and disease. Using UHPLC/HPLC with electrochemical detection or mass spectrometry, we deliver robust PK/PD data to support confident CNS decision making.




July 30, 2015

Inobrodib, an exciting, first-in-class oral anti-cancer drug in clinical development by CellCentric, was collaboratively designed, synthesised and supported on its pre-clinical journey by an integrated project team at Sygnature Discovery. Inobrodib is now showing promising results in Phase I and II trials for multiple myeloma and other cancer types.

At Sygnature Discovery, we deliver world-leading drug discovery solutions to accelerate your compound from idea to clinic.

Our leadership team brings diverse experience and insight, driving collaboration and innovation across drug discovery.

Explore careers at Sygnature Discovery and join a global team committed to science, collaboration, and integrity.
Inobrodib, an exciting, first-in-class oral anti-cancer drug in clinical development by CellCentric, was collaboratively designed, synthesised and supported on its pre-clinical journey by an integrated project team at Sygnature Discovery. Inobrodib is now showing promising results in Phase I and II trials for multiple myeloma and other cancer types.
At Sygnature Discovery, we deliver world-leading drug discovery solutions to accelerate your compound from idea to clinic.
Our leadership team brings diverse experience and insight, driving collaboration and innovation across drug discovery.
Explore careers at Sygnature Discovery and join a global team committed to science, collaboration, and integrity.
In structural biology, X‑ray crystallography, single‑particle cryo‑EM, and Nuclear Magnetic Resonance (NMR) have been instrumental in revealing the atomic-level structures of macromolecules, including peptides, proteins, glycoproteins, and nucleic acids. Among these approaches, NMR stands out for its unique ability to probe not only structure, but also molecular dynamics and interactions in solution under a wide range of physiologically relevant conditions. See our mini review on Protein NMR and its Role in Drug Discovery
Despite its versatility, NMR-based studies have historically faced a key limitation: the production of isotopically labelled proteins. Many established labelling strategies rely on Escherichia coli expression systems, which are not always suitable—particularly for complex eukaryotic proteins that require specialized folding machinery or post-translational modifications. This challenge is especially relevant for the systems discussed in this case study, which focuses exclusively on protein labelling in eukaryotic hosts.
It is important to note that both unlabelled and isotopically labelled macromolecules can be studied by NMR across a broad size range, from small molecules (~1 kDa) to megadalton complexes. However, isotopic enrichment becomes increasingly critical as molecular size increases. Proteins in the 3–20 kDa range typically only require uniform 15N or sometimes 15N/13C labelling, while those between 20–50 kDa often benefit from additional deuteration (2H). For larger systems (>50 kDa), extensive deuteration combined with selective 13C labelling of methyl groups (e.g., isoleucine, leucine, valine, alanine, methionine, and threonine) is generally necessary to obtain high-quality spectra.
In practice, the incorporation of stable isotopes (15N, 13C, and 2H) is achieved through de novo recombinant protein synthesis in cell culture or cell-free systems. Prokaryotic hosts—particularly E. coli—have been the workhorse of isotopic labelling due to their low cost, rapid growth, and adaptability to isotope-enriched media, including growth in 100% deuterium oxide (2H). These features make them especially well-suited for producing labelled proteins for NMR studies.
However, prokaryotic systems have significant limitations when compared to eukaryotic expression platforms. They often lack the cellular machinery required for proper folding of complex proteins, correct disulfide bond formation, and essential post-translational modifications such as phosphorylation, methylation, and glycosylation. Consequently, many human proteins cannot be reliably expressed in E. coli. To address these challenges, alternative eukaryotic systems—including yeast, insect cells, and mammalian cell lines such as CHO and HEK cells—have been developed. While these systems enable more biologically relevant protein production, they introduce new challenges, particularly in achieving efficient and cost-effective isotopic labelling for NMR applications.
In this context, a limited number of 15N‑ or 15N/13C‑labelling methodologies have been developed for yeast, insect, and CHO cells, with even fewer available for HEK cells. A major drawback of these approaches is the exceptionally high cost of isotopically enriched media, which typically ranges from approximately 3,500 to 6,500 USD per litre. These costs are often unsustainable for poorly expressed proteins or for high‑throughput NMR screening campaigns in fragment‑based drug discovery (FBDD).
To support NMR‑based FBDD for our current and future partners, we are pleased to announce the launch of an isotopic labelling service for proteins expressed in HEK-293E eukaryotic system. β2‑microglobulin (β2m) and one interleukin were used as model proteins to validate our capabilities.
Absolutely key to the success of this project was the input from our cell science team. The HEK293-6E cell line was adapted to an affordable custom media prior to developing and optimising a method for expressing isotopically labelled proteins in this system. Our in-house expertise with the HEK293-6Es was crucial for developing these new protocols, when at first achieving expression proved to be challenging. β2‑microglobulin (β2m) and one interleukin were used as model proteins to validate our capabilities.
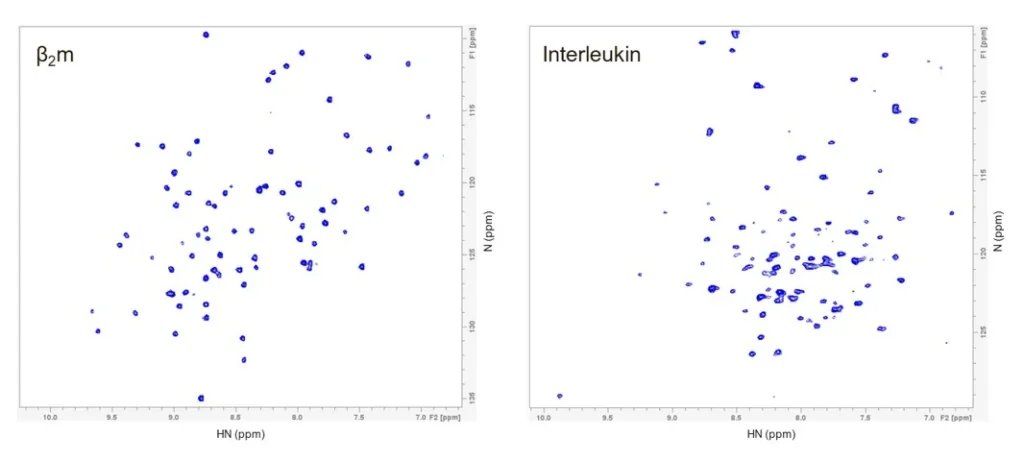
Both proteins were uniformly enriched with the 15N isotope and subsequently purified. Sample quality was assessed by 2D-NMR, focusing primarily on the amide resonances. The resulting spectra showed well‑dispersed and well‑defined resonances with good signal‑to‑noise ratios. For β2m, approximately 86 HN resonances were observed out of 94 expected. For the interleukin, ~102 HN resonances were identified out of 113 expected (Figure 1). Missing resonances for both proteins may be attributed to alternative conformations or post‑translational protein modifications; these aspects will be addressed in a forthcoming post in our NMR-blog series.
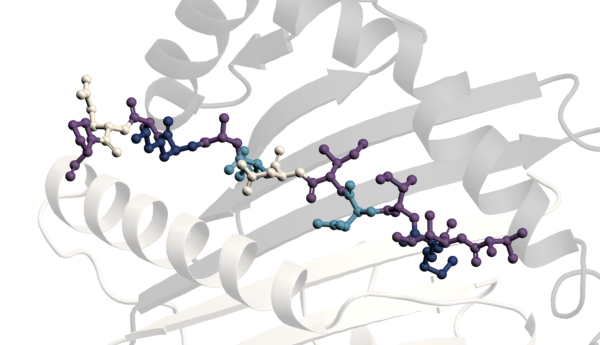
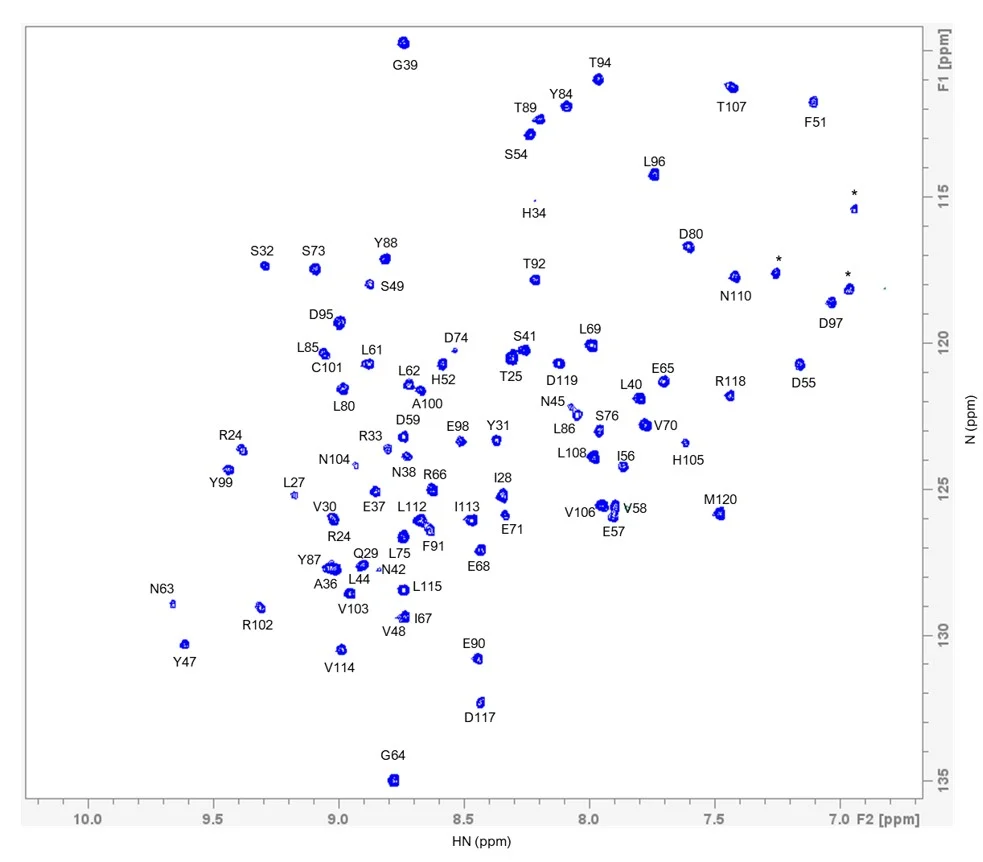
To demonstrate the potential of the isotopically labelled material, we selected β2m for further descriptive analysis. Based on the reported NMR assignments of β2m (BMRB: 51097; produced in E. coli), we were able to transfer approximately 96% (91 out of 94 expected) of the HN assignments to our sample (figure 2).
Subsequently, we continued with structural analysis of β2m assessed by NMR. Our findings suggest that β2m contains three distinct regions (1, 2 and 3) that appear to be less structured compared with the rest of the protein. These observations correlate well with the β2m three‑dimensional structure (PDB: 3CIQ), in which regions 1, 2, and 3 are located within the loops connecting the B–C, D1–E, and E–F β‑strands, respectively. In addition, our data suggest that the D2 β‑strand of β2m may also exhibit reduced structural order. See figure 3 for additional details.
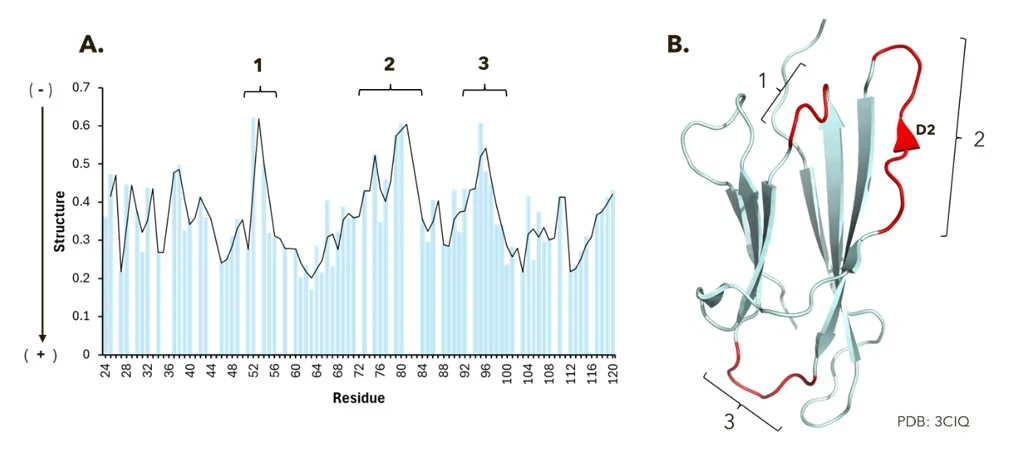
In summary, we successfully produced and isotopically labelled two human proteins using a eukaryotic expression system. In addition, we demonstrated the suitability of the produced material to support NMR studies. Please do not hesitate to contact us if you require any additional information or support for your current projects.



Peak Proteins, NuChem Sciences, and SB Drug Discovery have now fully integrated with Sygnature Discovery.
